Integracja systemu PIM (Product Information Management) z headless storefrontem to fundament nowoczesnego e-commerce, który pozwala skalować sprzedaż wielokanałową bez powielania danych i logiki biznesowej. W tej architekturze PIM staje się centralnym „mózgiem” danych produktowych, podczas gdy lekki frontend konsumuje je przez API, zapewniając elastyczność, szybkość i przewagę konkurencyjną. Poniżej znajdziesz konkretną wiedzę o projektowaniu modelu atrybutów, wariantów, integracji mediów i procesie publikacji zmian pod kątem headless commerce.
PIM jako single source of truth w architekturze headless
W modelu headless commerce PIM centralizuje opisy, parametry, relacje produktowe, lokalizacje i assety, dystrybuując je następnie do wszystkich punktów styku – od strony WWW przez aplikacje mobilne, aż po marketplace’y i systemy POS. Headless storefront (zbudowany np. w React, Vue czy Next.js) korzysta z PIM-u przez API (REST lub GraphQL), co pozwala mu niezależnie ewoluować, personalizować doświadczenie użytkownika i reagować na rosnący ruch.
Nowoczesne rozwiązania PIM – takie jak Akeneo, Pimcore, Crystallize czy Geins – projektowane są jako API-first / headless PIM, co znacznie ułatwia ich wpięcie w wielokanałowy ekosystem. Dla polskiego e-commerce to szczególnie istotne: podczas gdy na rynkach zachodnich PIM jest już standardem przy większych katalogach, my wciąż „doganiamy” ten trend. Właśnie dlatego integracja PIM-u z headless storefrontem pozwala obejść ograniczenia SaaS-owych platform (np. Shopify) w zakresie atrybutów, wariantów i dystrybucji wielokanałowej. Integracja ta umożliwia lepsze zarządzanie informacjami o produktach, co jest kluczowe dla efektywnej sprzedaży w różnych kanałach. Co to jest PIM w ecommerce? To system, który pozwala na centralizację danych produktowych, co znacznie ułatwia ich aktualizację i synchronizację na wielu platformach jednocześnie. Dzięki takim rozwiązaniom, polskie firmy zyskują konkurencyjność i mogą szybciej reagować na zmieniające się potrzeby rynku.
Protip: zanim wybierzesz PIM, sprawdź, czy oferuje stabilne publiczne API, SDK lub gotowe konektory do twojego ekosystemu – unikniesz kosztownych „customów” i przyspieszysz wdrożenie.
Model atrybutów pod headless storefront
Sposób, w jaki zaprojektujesz model atrybutów w PIM-ie, decyduje o tym, jak sprawnie dostarczysz dane do frontendu i pozostałych kanałów. W podejściu headless nie myślisz tylko o polu w bazie, ale przede wszystkim o kontrakcie API między PIM-em a storefrontem.
Kluczowe decyzje projektowe
Typy atrybutów obejmują pola tekstowe, numeryczne, listy wyboru, wielokrotny wybór, boolean, daty oraz relacyjne (np. do kategorii, kolekcji, akcesoriów). Zestawy atrybutów (attribute sets) grupują pola według typów produktów – „buty”, „laptopy” – co pozwala budować skalowalne modele i filtrowanie po stronie frontu.
Lokalizacje i kanały warto rozdzielić na atrybuty lokalizowalne (opis, tytuł, metatagi), globalne (EAN, wymiary) oraz kanałowo-specyficzne (np. skrócony opis dla marketplace).
Standardy branżowe – część PIM-ów wspiera ETIM, ECLASS, BMEcat, UNSPSC, co ułatwia B2B, integracje dystrybucyjne i ekspansję zagraniczną.
Jak myśleć o atrybutach w kontrakcie PIM → headless frontend:
oznaczaj atrybuty „core” (zawsze wymagane dla SEO/UX) oraz fakultatywne,
dodaj pola techniczne (search_tags, feature_flags, listing_badges), które frontend wykorzysta do sortowania, wyróżnień czy personalizacji,
projektuj nazwy atrybutów „API-friendly” (primary_image, brand_slug, size_guide_url), a nazwy UI trzymaj w warstwie tłumaczeń.
Warianty produktów – strategie modelowania
Warianty – rozmiary, kolory, konfiguracje – są krytyczne dla UX i kosztu integracji: błędne odwzorowanie skutkuje duplikacją logiki w frontach. PIM powinien być jedynym miejscem definicji struktury wariantów, natomiast headless storefront jedynie ją odczytuje.
Przykładowe odwzorowanie wariantu (logika dla frontu)
Obszar
Co trzyma PIM
Co robi headless storefront
Identyfikacja
ID produktu nadrzędnego, ID wariantu, SKU, EAN
mapuje wariant do koszyka, URL, śledzenia analytics
Atrybuty wariantu
np. color, size, material, fit
renderuje przełączniki (swatche, dropdowny), waliduje dostępne pary
Dostępność i cena
stock per SKU, cena bazowa, promo, kanałowe cenniki
pokazuje availability i cenę zależnie od wybranego wariantu i kanału
Logika UX
flagi np. default_variant, variant_sort_order, online_exclusive
wybór wariantu domyślnego, kolejność, odznaczenia w listingu
Media
przypisanie obrazów/360°/video do wariantów (np. konkretnego koloru)
przełączanie galerii po zmianie wariantu
Według analiz vendorów PIM, dobrze wdrożony system skraca „time to market” nowych produktów nawet o 30–50%, głównie dzięki automatyzacji atrybutów i wariantów (Stibo Systems).
Protip: staraj się, aby logika konfiguracji (np. które kombinacje rozmiar/kolor są dozwolone) była utrzymywana w PIM-ie jako dane, a nie „if-widły” w kodzie frontendu – przy dodaniu nowego kanału po prostu konsumujesz istniejący model.
Prompt: Zaprojektuj model wariantów dla swojego produktu
Chcesz szybko zaprojektować strukturę wariantów i atrybutów dla konkretnego produktu? Przekopiuj poniższy prompt i wklej go do modelu AI, którego używasz na co dzień (np. Chat GPT, Gemini, Perplexity) lub skorzystaj z naszych autorskich generatorów biznesowych dostępnych na stronie narzędzia lub kalkulatorów branżowych kalkulatory.
Jestem właścicielem sklepu e-commerce i planuję wdrożenie systemu PIM z headless storefrontem.
Pomóż mi zaprojektować model wariantów dla produktu: [NAZWA_PRODUKTU].
Produkt dostępny jest w następujących wymiarach zmienności: [NP. KOLOR, ROZMIAR, MATERIAŁ].
Kanały sprzedaży: [NP. WWW, MARKETPLACE, B2B].
Specyficzne wymagania: [NP. RÓŻNE CENY DLA KANAŁÓW, OGRANICZONA DOSTĘPNOŚĆ NIEKTÓRYCH WARIANTÓW].
Przygotuj:
1. Strukturę atrybutów wariantów (nazwy, typy, czy są kanałowo-specyficzne)
2. Sugestię modelu master/child lub alternatywnego podejścia
3. Mapowanie wariantów do API (jak frontend powinien konsumować dane)
4. Listę pól technicznych pomocnych dla UX (np. default_variant, badges)
Integracja mediów i DAM z headless storefrontem
Media produktowe stanowią jeden z najsłabszych punktów tradycyjnych integracji – w modelu headless warto opierać je o PIM + DAM + CDN. Taka kombinacja umożliwia spójne UX na WWW, w aplikacji mobilnej i na marketplace’ach, bez duplikowania assetów.
Rola PIM i DAM:
PIM trzyma referencje do mediów (ID, URL, warianty rozdzielczości, „role” obrazów) oraz powiązania media ↔ warianty (np. zdjęcia tylko dla danego koloru),
CDN serwuje media blisko użytkownika, minimalizując opóźnienia; wiele rozwiązań DAM/PIM (np. Cloudinary, Crystallize) ma wbudowaną dystrybucję CDN.
Praktyki integracyjne
Zdefiniuj role assetów (thumbnail, gallery, zoom, hero, variant_image, user_manual_pdf), aby frontend mógł łatwo zdecydować, co gdzie pokazać. Przewiduj transformacje po stronie URL (np. parametry rozmiaru, jakości, formatu WebP/AVIF) zamiast generować wiele plików per wariant. Powiąż media z kanałami (np. inne hero zdjęcia dla B2B, inne dla marketplace), aby headless frontend otrzymywał dokładnie ten zestaw, który obowiązuje dla danego kontekstu.
Publikacja zmian – workflow, wersjonowanie, kanały
Jedna z największych przewag PIM-u w modelu headless to kontrola nad cyklem życia danych produktowych i ich publikacją do wielu kanałów. Integracja z headless storefrontem musi uwzględniać workflow, wersjonowanie i strategię propagacji.
Typowe procesy publikacji
Workflow redakcyjny obejmuje statusy typu draft, in review, approved, published, czasem osobno per kanał (np. opublikowany na WWW, ale nie na marketplace). Reguły kompletności wymuszają określony poziom kompletności (np. 100% wymaganych atrybutów, min. 3 zdjęcia, SEO metadane) zanim produkt może zostać opublikowany. Wersjonowanie umożliwia powrót do poprzedniej wersji opisu, porównywanie zmian, audyt (kto co zmienił). Publikacja zaplanowana pozwala planować start kampanii, sezonowość czy wprowadzenie nowej kolekcji.
Protip: wdrażając PIM w polskim sklepie, zacznij od prostego modelu statusów i kompletności, rozbudowując workflow dopiero z czasem – zbyt skomplikowane procesy od razu potrafią sparaliżować adopcję w zespole.
Kanałowe strategie publikacji do headless storefrontu
Push (event-driven) – PIM wysyła webhook lub wiadomość do brokera (np. Kafka, RabbitMQ), a headless backend/front agreguje zmiany i aktualizuje cache/indeksy,
Pull (polling / on demand) – frontend lub backend okresowo pobiera zmiany (np. updated_since) albo ładuje dane na żądanie użytkownika,
Hybrida – eventy z PIM-u służą do odświeżania indeksów i cache’y, ale frontend zawsze może „dociągnąć” najświeższe dane przy kluczowych operacjach (np. dodanie do koszyka).
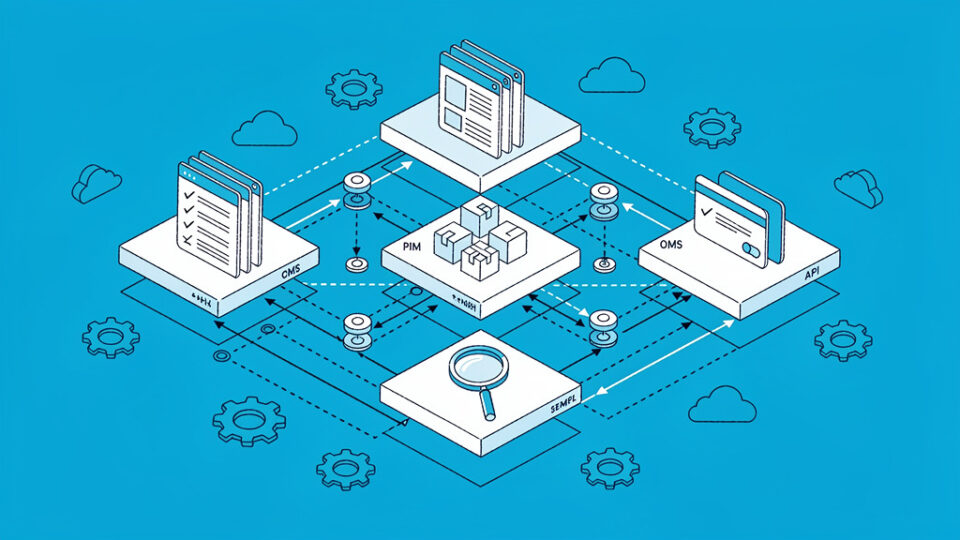
Architektura integracji PIM ↔ headless storefront
Komponując integrację, trzeba pogodzić wydajność, elastyczność i prostotę utrzymania. Poniżej trzy typowe wzorce:
Frontend → Backend for Frontend (BFF) → PIM
BFF agreguje dane z PIM-u, systemu koszykowego, CMS-u i innych usług, wystawiając uproszczone API pod konkretne fronty (web, mobile). Zaleta: mniejsza liczba zapytań z frontu, centralne miejsce logiki mapowania i fallbacków.
Search index (np. Elasticsearch, Algolia) zasilany z PIM
PIM jest źródłem danych, ale frontend pobiera listingi i podstawowe pola z indeksu wyszukiwarki, a szczegóły „długiego ogona” (np. opisy w koszyku) dociąga bezpośrednio z PIM-u. Rozwiązanie to oszczędza API PIM-u przy dużym ruchu, szczególnie przy filtrach i sortowaniu.
Static/Incremental pre-rendering + PIM
W architekturze Jamstack (Next.js, Gatsby) część stron produktowych może być prerenderowana w oparciu o dane z PIM-u, a zmiany odświeżane przez webhooki. Podejście to dobrze łączy SEO/Performance z headlessową elastycznością.
Protip: w projektach, gdzie zespół ma małe doświadczenie z PIM-em, warto najpierw wdrożyć system na jednym kanale (np. tylko WWW) i dopiero po ustabilizowaniu procesów „podpiąć” kolejne – zmniejsza to ryzyko paraliżu operacyjnego.
Najczęstsze błędy i gotowe recepty dla polskiego sklepu
W polskich wdrożeniach PIM+headless często powtarzają się te same problemy:
Typowe błędy:
przenoszenie do PIM-u chaosu z Excela 1:1, bez uprzedniego czyszczenia, deduplikacji i ustandaryzowania danych (jednostki, kody, słowniki),
traktowanie PIM-u jako „łącznika do ERP”, zamiast jako centralnej warstwy produktowej między ERP, DAM, CMS, marketplace’ami i frontami,
brak konsekwentnego modelu kanałowego – te same dane dla wszystkich kanałów, co prowadzi do kompromisów w UX,
budowanie „magii” po stronie frontu (np. mapowanie wariantów, nazewnictwa, kategorii) zamiast w PIM-ie – skutkuje trudnym utrzymaniem i powielaniem logiki.
zdefiniuj minimalny, ale stabilny rdzeń modelu danych: typy produktów, atrybuty core, model wariantów, role mediów, statusy i kanały,
na etapie developmentu frontu traktuj API PIM-u jak kontrakt, który nie może się zmieniać „z dnia na dzień” – wykorzystaj wersjonowanie API albo warstwę pośrednią (BFF).
Integracja PIM-u z headless storefrontem to inwestycja w elastyczność i przewagę konkurencyjną. Dzięki przemyślanemu modelowi atrybutów, wariantów, integracji mediów i kontrolowanej publikacji zmian zyskujesz spójność danych w wielu kanałach i skracasz time-to-market nowych produktów – nawet o połowę. W polskim e-commerce ten trend dopiero nabiera rozpędu, więc teraz jest idealny moment, by zbudować przewagę technologiczną.
Redakcja
Na ecommerceblog.pl pomagamy właścicielom sklepów internetowych budować przewagę technologiczną, wdrażając rozwiązania typu headless oraz AI i dostarczając zasoby na temat najnowszych trendów w e-handlu oraz strategii biznesowych. Wspieramy w cyfrowej transformacji, ucząc, jak wykorzystać nowoczesne technologie do dominacji na rynku.
Newsletter
Subskrybuj dawkę wiedzy
Wypróbuj bezpłatne narzędzia
Skorzystaj z narzędzi, które ułatwiają codzienna pracę!
Integracja z zewnętrznymi systemami w architekturze headless commerce przypomina chodzenie po polu minowym. Źle zaprojektowany…
Redakcja
10 listopada 2025
Zarządzaj zgodą
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.